library(tidyverse)
library(readxl)
path = "files/CH-177 Table Transformation.xlsx"
input = read_excel(path, range = "C2:C24")
test = read_excel(path, range = "E2:G12")
result = input %>%
mutate(col = case_when(
str_detect(`Column 1`, "[0-9]{5}") ~ 1,
str_detect(`Column 1`, "[A-Z]{1}") ~ 2,
TRUE ~ 3)) %>%
mutate(Date = ifelse(col == 1, `Column 1`, NA)) %>%
fill(Date, .direction = "down") %>%
mutate(Quantity = ifelse(col == 3, `Column 1`, NA)) %>%
fill(Quantity, .direction = "up") %>%
filter(col == 2) %>%
select(Date, Product=`Column 1`, Quantity) %>%
mutate(Date = janitor::excel_numeric_to_date(as.numeric(Date)) %>% as.POSIXct(),
Quantity = as.numeric(Quantity))
all.equal(result, test, check.attributes = FALSE)
#> [1] TRUEOmid - Challenge 177
data-challenges
advanced-exercises
🔰 Table Transformation!
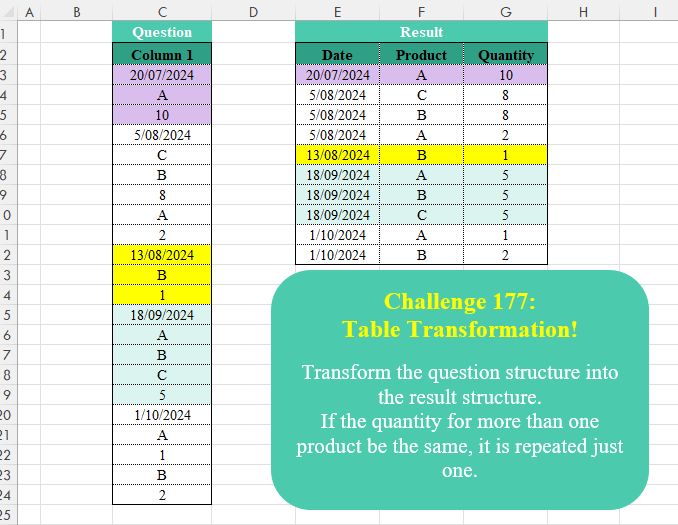
Challenge Description
🔰 Table Transformation!
Solutions
Logic:
Reads the workbook ranges needed for the challenge
Builds the intermediate columns that drive the final result
Parses the text patterns directly instead of relying on manual cleanup
Strengths:
- The R solution stays close to the workbook rule and keeps the transformation compact.
Areas for Improvement:
- The code assumes the sheet structure and source ranges remain stable.
Gem:
- The strongest part of the solution is choosing the right intermediate representation before shaping the final output.
import pandas as pd
import numpy as np
import re
path = "CH-177 Table Transformation.xlsx"
input = pd.read_excel(path, usecols="C", skiprows=1, nrows=22, names=["Column 1"])
test = pd.read_excel(path, usecols="E:G", skiprows=1, nrows=10)
input['col'] = input['Column 1'].apply(lambda x: 3 if re.match(r'^\d+$', str(x)) else (2 if re.match(r'^[A-Za-z]', str(x)) else 1))
input['Date'] = np.where(input['col'] == 1, input['Column 1'], np.nan)
input['Date'] = input['Date'].ffill()
input['Quantity'] = np.where(input['col'] == 3, input['Column 1'], np.nan)
input['Quantity'] = input['Quantity'].bfill()
result = input[input['col'] == 2][['Date', 'Column 1', 'Quantity']].reset_index(drop=True)
result.columns = ['Date', 'Product', 'Quantity']
print(result.equals(test)) #TrueLogic:
Reads the workbook ranges needed for the challenge
Parses the text patterns directly instead of relying on manual cleanup
Strengths:
- The Python version follows the same rule in a direct dataframe-oriented implementation.
Areas for Improvement:
- The code assumes the workbook layout remains stable, so any sheet redesign would require small adjustments.
Gem:
- The implementation stays close to the original workbook rule instead of adding unnecessary abstraction.
Difficulty Level
This task is moderate:
The core logic is clear, but the correct transformation pattern is not obvious from the raw input.
The challenge combines multiple reshaping, grouping, or parsing steps.