library(tidyverse)
library(readxl)
path = "files/CH-174 Filtering.xlsx"
input = read_excel(path, range = "C2:D25")
test = read_excel(path, range = "F2:G7")
result = input %>%
filter(!pmax(lag(Value, 1, default = 0) > Value,
lag(Value, 2, default = 0) > Value,
lead(Value, 1, default = 0) > Value,
lead(Value, 2, default = 0) > Value))
all.equal(result, test, check.attributes = FALSE)Omid - Challenge 174
data-challenges
advanced-exercises
The task is to filter out rows where there is a greater value within two days before or after the current row. For example, if a value at a given row is…
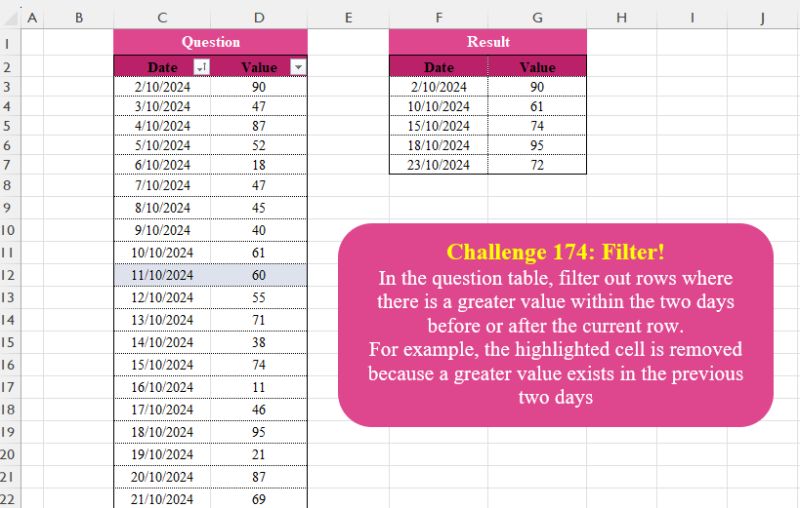
Challenge Description
The task is to filter out rows where there is a greater value within two days before or after the current row. For example, if a value at a given row is less than any value in the range of two rows before and after, it is excluded.
🔗 Link to Excel file: 👉https://lnkd.in/gV9WvDx62
Solutions
Logic:
lag(Value, n): Accesses then-th previous row value for comparison.lead(Value, n): Accesses then-th next row value for comparison.pmax(...): Evaluates whether any of the lagged or lead values are greater than the current value.!pmax(...): Negates the result to keep rows where no greater value exists in the two-day window.
Strengths:
Conciseness: The use of
lag,lead, andpmaxmakes the logic clear and compact.Clarity: The logic directly mirrors the task requirements.
Areas for Improvement:
- Edge Cases: Ensure
default = 0is appropriate for the dataset. For example, if negative values are present,0may not work as a default.
- Edge Cases: Ensure
Gem:
- The combination of
lag,lead, andpmaxelegantly captures the two-day filtering logic in a straightforward manner.
- The combination of
import pandas as pd
path = "CH-174 Filtering.xlsx"
input = pd.read_excel(path, usecols="C:D", skiprows=1, nrows=24, names=['Index', 'Value'])
test = pd.read_excel(path, usecols="F:G", skiprows=1, nrows=5, names=['Index', 'Value'])
def filter_values(df):
df['All_Lagged_Lead_Lower'] = (df['Value'].shift(1, fill_value=0) < df['Value']) & \
(df['Value'].shift(2, fill_value=0) < df['Value']) & \
(df['Value'].shift(-1, fill_value=0) < df['Value']) & \
(df['Value'].shift(-2, fill_value=0) < df['Value'])
return df[df['All_Lagged_Lead_Lower']][['Index', 'Value']]
result = filter_values(input).reset_index(drop=True)
print(result.equals(test)) # TrueLogic:
shift(n): Retrieves the valuenrows before (n > 0) or after (n < 0) the current row.Logical AND (
&): Ensures the current value is greater than all lagged and lead values within the two-day window.fill_value=0: Handles edge cases where lagged or lead values do not exist.
Strengths:
Explicit Logic: The filtering logic is broken into a clear, step-by-step process.
Reusability: Encapsulating the logic in a function (
filter_values) makes it easy to apply to other datasets.
Areas for Improvement:
- Efficiency: While readable, the row-wise filtering (
shiftand comparison) could be computationally expensive for large datasets.
- Efficiency: While readable, the row-wise filtering (
Gem:
- The use of
shiftwithfill_value=0handles edge cases gracefully and ensures no missing data in comparisons.
- The use of
Difficulty Level
This task is moderate to challenging:
Requires a strong understanding of row-wise operations and lag/lead handling.
Balancing edge case handling (e.g., first and last rows) with efficiency can be non-trivial.