library(tidyverse)
library(readxl)
path = "Power Query/PQ_Problem_256.xlsx"
input = read_excel(path, range = "A1:I4")
test = read_excel(path, range = "A8:C17")
result = input %>%
mutate(T2 = `Start Date Time` + minutes(Dur1),
T3 = T2 + minutes(Dur2),
T4 = T3 + minutes(Dur3),
T5 = T4 + minutes(Dur4),
T6 = T5 + minutes(Dur5),
T7 = T6 + minutes(Dur6),
T8 = T7 + minutes(Dur7)) %>%
select(-c(starts_with("Dur"))) %>%
rename(T1 = `Start Date Time`) %>%
pivot_longer(cols = -State, names_to = "ID", values_to = "Time") %>%
na.omit() %>%
mutate(order = (as.numeric(str_extract(ID, "\\d")) + 1) %/% 2 ,
ID = ifelse(as.numeric(str_extract(ID, "\\d")) %% 2 == 0, "To", "From")) %>%
pivot_wider(names_from = ID, values_from = Time) %>%
select(State, From, To)
all.equal(result, test)
#> [1] TRUEExcel BI - PowerQuery Challenge 256
excel-challenges
power-query
State Start Date Time Dur1 Dur2 Dur3 Dur4
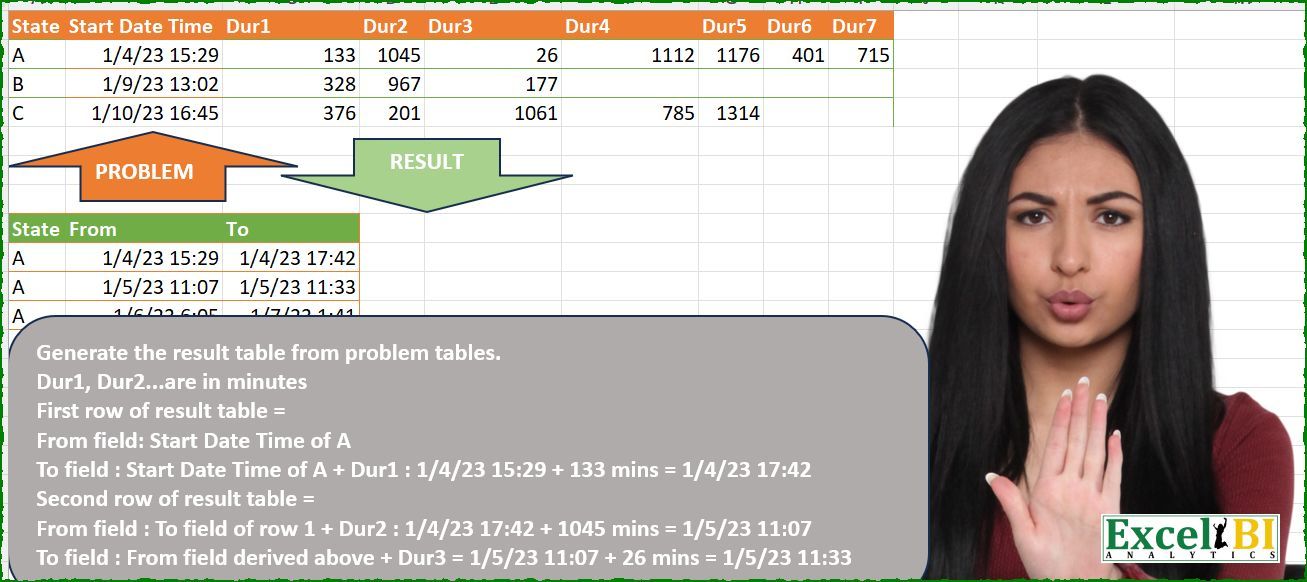
Challenge Description
State Start Date Time Dur1 Dur2 Dur3 Dur4
Solutions
Logic:
Reads the workbook range needed for the challenge
Reshapes the data into the structure required by the result table
Builds helper columns that drive the final output
Uses direct pattern parsing where the workbook encodes logic in text
Strengths:
- The R solution stays close to the workbook logic and keeps the transformation compact.
Areas for Improvement:
- The code assumes the workbook layout and selected ranges remain stable.
Gem:
- The best part of the solution is choosing the right intermediate shape before formatting the final output.
import pandas as pd
import numpy as np
path = "PQ_Problem_256.xlsx"
input = pd.read_excel(path, usecols="A:I", nrows=4)
test = pd.read_excel(path, usecols="A:C", skiprows=7, nrows=10)
for i in range(1, 8):
input[f'T{i+1}'] = input[f'T{i}'] + pd.to_timedelta(input[f'Dur{i}'], unit='m') if i > 1 else input['Start Date Time'] + pd.to_timedelta(input[f'Dur{i}'], unit='m')
input.drop(columns=[col for col in input.columns if col.startswith('Dur')], inplace=True)
input.rename(columns={'Start Date Time': 'T1'}, inplace=True)
result = input.melt(id_vars=['State'], var_name='ID', value_name='Time').dropna()
result['order'] = result['ID'].str.extract(r'(\d)').astype(int).add(1).floordiv(2)
result['ID'] = np.where(result['ID'].str.extract(r'(\d)').astype(int).mod(2).eq(0), 'To', 'From')
result = result.pivot(index=['State', 'order'], columns='ID', values='Time').reset_index().rename_axis(None, axis=1)[['State', 'From', 'To']]
print(test.equals(result)) # TrueLogic:
Reads the workbook range needed for the challenge
Reshapes the data into the structure required by the result table
Uses direct pattern parsing where the workbook encodes logic in text
Applies the rule iteratively until the output is complete
Strengths:
- The Python version follows the same workbook rule in a direct pandas-oriented implementation.
Areas for Improvement:
- As with the R version, any workbook layout change would require small adjustments.
Gem:
- The implementation stays close to the source challenge instead of adding unnecessary abstraction.
Difficulty Level
This task is moderate:
It combines reshaping, grouping, or parsing steps that are common in Power Query style problems.
The main challenge is reproducing the workbook output structure exactly.