library(tidyverse)
library(readxl)
library(janitor)
path = "files/CH-181 Table Transformation.xlsx"
input = read_excel(path, range = "C2:C41", col_types = "text")
test = read_excel(path, range = "E2:H9") %>%
mutate(From = as.Date(From),
To = as.Date(To))
result = input %>%
mutate(row = cumsum(str_detect(Name, "^[A-Z]{3}$"))) %>%
fill(row, .direction = "down") %>%
group_by(row) %>%
mutate(Name1 = first(Name[str_detect(Name, "^[A-Z]{3}$")]),
prop = ifelse(Name %in% c("From", "To", "Status"), Name, NA)) %>%
fill(prop, .direction = "down") %>%
filter(Name != prop | is.na(prop)) %>%
pivot_wider(names_from = prop, values_from = Name) %>%
mutate(From = excel_numeric_to_date(as.numeric(From)),
To = excel_numeric_to_date(as.numeric(To))) %>%
ungroup() %>%
select(Name = Name1, From, To, Status)
all.equal(result, test)
# [1] TRUEOmid - Challenge 181
data-challenges
advanced-exercises
🔰 Table Transformation!
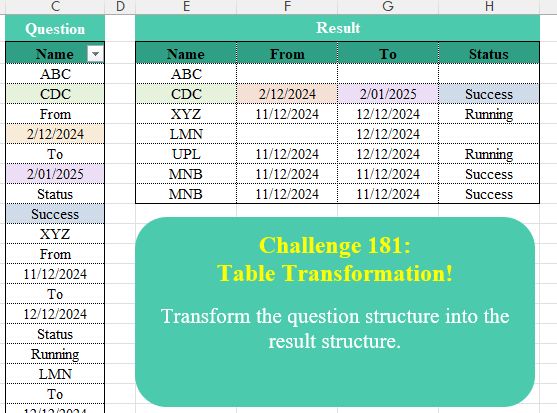
Challenge Description
🔰 Table Transformation!
Solutions
Logic:
Reads the workbook ranges needed for the challenge
Reshapes the data into the grain required by the task
Aggregates or ranks values at the relevant grouping level
Builds the intermediate columns that drive the final result
Strengths:
- The R solution stays close to the workbook rule and keeps the transformation compact.
Areas for Improvement:
- The code assumes the sheet structure and source ranges remain stable.
Gem:
- The strongest part of the solution is choosing the right intermediate representation before shaping the final output.
import pandas as pd
import numpy as np
path = "CH-181 Table Transformation.xlsx"
input = pd.read_excel(path, usecols="C", skiprows=1, nrows=40, dtype=str)
test = pd.read_excel(path, usecols="E:H", skiprows=1, nrows=7).rename(columns=lambda x: x.split('.')[0])
test['From'] = pd.to_datetime(test['From'], errors='coerce').dt.date
test['To'] = pd.to_datetime(test['To'], errors='coerce').dt.date
input['row'] = input['Name'].str.match(r'^[A-Z]{3}$').cumsum()
input['row'] = input['row'].ffill()
grouped = input.groupby('row')
input['Name1'] = grouped['Name'].transform(lambda x: x[x.str.match(r'^[A-Z]{3}$')].iloc[0])
input['prop'] = np.where(input['Name'].isin(['From', 'To', 'Status']), input['Name'], np.nan)
input['prop'] = input['prop'].ffill()
filtered = input.groupby('row').apply(lambda x: x[~((x['Name'] == x['prop']) & x['prop'].notna())]).reset_index(drop=True)
filtered['prop'] = np.where(filtered['Name'] == filtered['Name1'], 'Name', filtered['prop'])
result = filtered.pivot(index='row', columns='prop', values='Name').reset_index(drop=True)
result['From'] = pd.to_datetime(result['From'], errors='coerce').dt.date
result['To'] = pd.to_datetime(result['To'], errors='coerce').dt.date
result = result[['Name', 'From', 'To', 'Status']]
result = result.rename_axis(None, axis=1)
print(result.equals(test)) # TrueLogic:
Reads the workbook ranges needed for the challenge
Reshapes the data into the grain required by the task
Aggregates or ranks values at the relevant grouping level
Strengths:
- The Python version follows the same rule in a direct dataframe-oriented implementation.
Areas for Improvement:
- The code assumes the workbook layout remains stable, so any sheet redesign would require small adjustments.
Gem:
- The implementation stays close to the original workbook rule instead of adding unnecessary abstraction.
Difficulty Level
This task is moderate:
The core logic is clear, but the correct transformation pattern is not obvious from the raw input.
The challenge combines multiple reshaping, grouping, or parsing steps.