library(tidyverse)
library(readxl)
path = "files/CH-175 Remove consecutive X.xlsx"
input = read_excel(path, range = "C2:D10")
test = read_excel(path, range = "G2:G10") %>%
replace(is.na(.), "")
result = input %>%
mutate(ID = str_remove_all(ID, "[xX]{2,}")) %>%
select(ID)
all.equal(result, test, check.attributes = FALSE)Omid - Challenge 175
data-challenges
advanced-exercises
🔰 In the ID column, remove all instances of ‘X’ if it appears consecutively more than once.
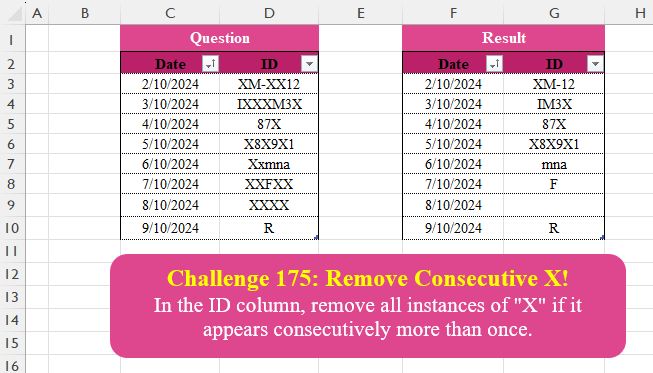
Challenge Description
🔰 In the ID column, remove all instances of “X” if it appears consecutively more than once.
🔗 Link to Excel file: 👉https://lnkd.in/gNWC_HzJ
Solutions
Logic:
str_remove_all(ID, "[xX]{2,}"): Matches two or more consecutivexorXand removes them from the string.replace(is.na(.), ""): HandlesNAvalues by replacing them with an empty string.
Strengths:
Conciseness: The
mutateandstr_remove_allfunctions make the transformation clear and efficient.Robustness: Handles missing values (
NA) gracefully.
Areas for Improvement:
- None; the solution is well-suited for the task.
Gem:
- The use of
str_remove_allsimplifies the regex operation, keeping the code compact and readable.
- The use of
import pandas as pd
import re
path = "CH-175 Remove consecutive X.xlsx"
input = pd.read_excel(path, usecols="C:D", skiprows=1, nrows=9)
test = pd.read_excel(path, usecols="G", skiprows=1, nrows=9).fillna("").rename(columns=lambda x: x.split('.')[0])
input['ID'] = input['ID'].apply(lambda x: re.sub(r'[xX]{2,}', '', x))
print(input[['ID']].equals(test)) # TrueLogic:
re.sub(r'[xX]{2,}', '', x): This regex matches two or more consecutivexorXcharacters and removes them.apply: Applies the regex substitution to each value in theIDcolumn.
Strengths:
Efficiency: Regex handles all consecutive cases in a single pass.
Clarity: The regex pattern is straightforward and self-explanatory.
Areas for Improvement:
- Edge Cases: If the
IDcolumn containsNaN, ensure these are handled gracefully.
- Edge Cases: If the
Gem:
- The use of
[xX]{2,}in regex is concise and effectively handles both lowercase and uppercaseX.
- The use of
Difficulty Level
This task is moderate to challenging:
Requires a strong understanding of row-wise operations and lag/lead handling.
Balancing edge case handling (e.g., first and last rows) with efficiency can be non-trivial.