library(tidyverse)
library(readxl)
path = "files/CH-173 Custom Grouping.xlsx"
input = read_excel(path, range = "B2:C26")
test = read_excel(path, range = "G2:I26")
result = input %>%
group_by(month(Date)) %>%
mutate(Group = paste0(month(Date), "-", pmin(row_number(), rev(row_number())))) %>%
ungroup() %>%
select(Date, Quantity, Group)
all.equal(result, test, check.attributes = FALSE)
#> [1] TRUEOmid - Challenge 173
data-challenges
advanced-exercises
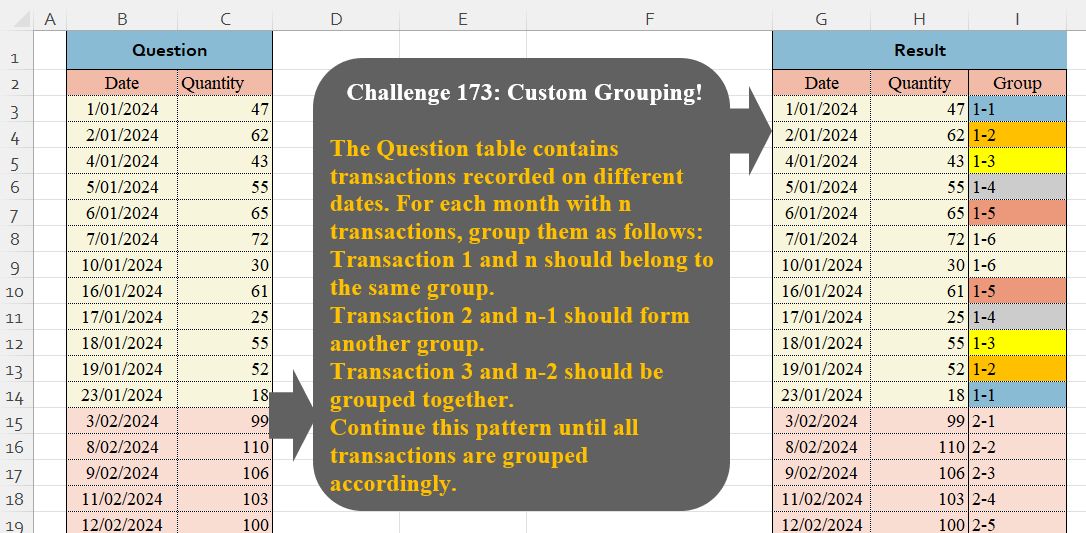
🔰 The Question table contains transactions recorded on different dates. For each month with n transactions, group them as follows:Transaction 1 and n…
Challenge Description
🔰 The Question table contains transactions recorded on different dates. For each month with n transactions, group them as follows:Transaction 1 and n should belong to the same group.Transaction 2 and n-1 should form another group.Transaction 3 and n-2 should be grouped together.Continue this pattern until all transactions are grouped accordingly.
🔗 Link to Excel file: 👉https://lnkd.in/gQsuEcCQ2
Solutions
Logic:
group_by(month(Date)): Groups transactions by month.row_number()andrev(row_number()): Calculates the position of the current row and its corresponding opposite row (e.g., 1st with last).pmin(): Takes the smaller of the two positions, ensuring proper pairing.paste0(month(Date), "-"): Prefixes each group with the month’s number for clarity.
Strengths:
Conciseness: The use of
pminandrevin a groupedmutateis elegant and compact.Readability: Clear grouping logic and alignment with the task.
Areas for Improvement:
- Flexibility: This code assumes all rows in the dataset have valid dates. Handling missing or invalid dates would make it more robust.
Gem:
- The combination of
pmin(row_number(), rev(row_number()))dynamically handles pairing in one step.
- The combination of
import pandas as pd
path = "CH-173 Custom Grouping.xlsx"
input = pd.read_excel(path, usecols="B:C", skiprows=1, nrows=25)
test = pd.read_excel(path, usecols="G:I", skiprows=1, nrows=25).rename(columns=lambda x: x.split('.')[0])
input['Month'] = input['Date'].dt.month
input['Group'] = input.groupby('Month').cumcount() + 1
input['Group'] = input.apply(lambda x: f"{x['Month']}-{min(x['Group'], len(input[input['Month'] == x['Month']]) - x['Group'] + 1)}", axis=1)
result = input[['Date', 'Quantity', 'Group']]
print(result.equals(test)) # TestLogic:
The regex pattern ([+-])(?= is identical to the R solution and functions in the same manner.
re.sub is used alongside a helper function switch_sign to replace the matched signs dynamically.
Strengths:
Modularity: The switch_sign function is a reusable and modular approach to handling the sign inversion.
Readability: The solution is straightforward, with logical steps for processing the data.
Areas for Improvement:
Edge Cases: Similar to the R solution, additional testing for unusual input formats would enhance robustness.
Performance: While the solution works efficiently for small datasets, larger datasets might benefit from vectorized operations in pandas rather than row-wise application.
Gems:
The use of re.sub with a custom function ensures flexibility in extending or modifying the logic.
Applying result.equals(test[‘Answer Expected’]) ensures validation of correctness.
Difficulty Level
This task is moderate to high difficulty:
Requires a good understanding of grouping, row-wise operations, and reverse indexing.
Balancing code efficiency and readability adds complexity.