library(tidyverse)
library(readxl)
path = "Power Query/PQ_Challenge_253.xlsx"
input = read_excel(path, range = "A1:D12")
test = read_excel(path, range = "G1:H18")
result = input %>%
mutate(Name1 = str_replace(Name1, "`", lead(Name1))) %>%
nest(data = -c(Name1, Serial, Name2)) %>%
mutate(Serial2 = row_number(), .by = Serial) %>%
unnest(data) %>%
mutate(Serial3 = row_number(), .by = c(Serial2, Serial)) %>%
mutate(Serial2 = ifelse(is.na(Name2), NA, Serial2),
Serial3 = ifelse(is.na(Name3), NA, Serial3)) %>%
mutate(level1 = paste(Name1, Serial),
level2 = paste(Name2, Serial, Serial2),
level3 = paste(Name3, Serial, Serial2, Serial3))
r2 = bind_rows(result %>% select(level = level1),
result %>% select(level = level2),
result %>% select(level = level3)) %>%
as_tibble() %>%
filter(!str_detect(level, "NA")) %>%
distinct() %>%
separate(level, c("Names", "Serial"), sep = " ", extra = "merge") %>%
mutate(Serial = str_replace_all(Serial, " ", ".")) %>%
select(Serial, Names) %>%
arrange(Serial)
all.equal(r2, test, check.attributes = FALSE)
# [1] TRUEExcel BI - PowerQuery Challenge 253
excel-challenges
power-query
Transpose the data given in problem table to hierarchal data in result table
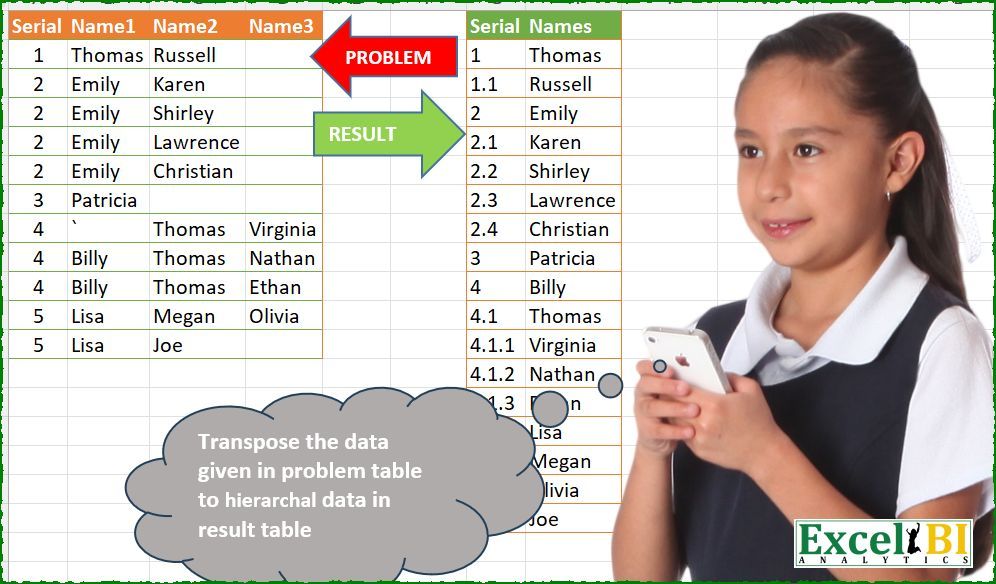
Challenge Description
Transpose the data given in problem table to hierarchal data in result table
🔗 Link to Excel file: 👉https://lnkd.in/d6w6XQJD
Solutions
Logic:
mutate(Name1 = ...): Handles placeholder replacement.nestandunnest: Organizes data into hierarchical groups bySerialandName2.row_number: Assigns serial numbers (Serial2,Serial3) to create hierarchy levels.bind_rows: Combines levels into a single structure for further processing.str_replace_allandseparate: Cleans and separates fields for the final result.
Strengths:
Hierarchical Grouping: Nested structures and row numbering effectively manage hierarchy levels.
Data Cleaning: Handles missing values (
NA) and placeholder replacement elegantly.
Areas for Improvement:
- Scalability: Handling very large datasets might require performance optimizations.
Gem:
- The combination of
nestandrow_numberdynamically builds hierarchical levels.
- The combination of
import pandas as pd
import numpy as np
path = "PQ_Challenge_253.xlsx"
input_df = pd.read_excel(path, usecols="A:D", nrows=11)
test_df = pd.read_excel(path, usecols="G:H", nrows=18).rename(columns=lambda x: x.split('.')[0])
input_df['Name1'] = input_df['Name1'].str.replace('`', 'Billy') # hardcoded
input_df['Serial2'] = input_df.groupby('Serial')['Name2'].transform(lambda x: pd.factorize(x)[0] + 1).replace(0, np.nan).astype('Int64')
input_df['Serial3'] = input_df.groupby(['Serial', 'Serial2'])['Name3'].transform(lambda x: pd.factorize(x)[0] + 1).replace(0, np.nan).astype('Int64')
input_df['level1'] = input_df['Name1'] + ' ' + input_df['Serial'].astype(str)
input_df['level2'] = input_df['Name2'] + ' ' + input_df['Serial'].astype(str) + '.' + input_df['Serial2'].astype(str)
input_df['level3'] = input_df['Name3'] + ' ' + input_df['Serial'].astype(str) + '.' + input_df['Serial2'].astype(str) + '.' + input_df['Serial3'].astype(str)
result = pd.concat([
input_df[['level1']].rename(columns={'level1': 'level'}),
input_df[['level2']].rename(columns={'level2': 'level'}),
input_df[['level3']].rename(columns={'level3': 'level'})
])
result = result.dropna().drop_duplicates()
result[['Names', 'Serial']] = result['level'].str.split(' ', n=1, expand=True)
result = result[['Serial', 'Names']].sort_values(by='Serial').reset_index(drop=True)
print(result.equals(test_df)) # TrueLogic:
Placeholder replacement: Handles specific placeholders like backticks in
Name1.pd.factorize: Creates unique group indices for hierarchical levels.concat: Combines levels (level1,level2,level3) into a single DataFrame.splitandsort_values: Splits and cleans hierarchical levels for output.
Strengths:
Hierarchical Handling:
groupbyandfactorizeprovide a robust method for creating hierarchy levels.Flexibility: The logic adapts to various scenarios (e.g., missing values).
Areas for Improvement:
- Hardcoding: Avoid hardcoding replacements like backticks; use a dynamic approach.
Gem:
- The use of
factorizeto generate unique indices for hierarchical levels is efficient and scalable.
- The use of
Difficulty Level
This task is moderate to high difficulty:
Requires understanding of hierarchical data structuring.
Involves dynamic group creation and data cleaning.